Parce que chez Craft AI nous pensons qu’une IA performante est avant tout une IA sécurisé, nos experts tech vous invitent à découvrir les différents types d’attaques visant les systèmes d’IA générative et comment s’en prémunir.
·
Jan 15, 2026
Dans l’univers IA, un système fait souvent parler de lui : celui de l’IA générative. Elle fait désormais partie intégrante de notre quotidien : ChatGPT, Gemini, Claude… Autant de solutions que des millions de personnes utilisent désormais chaque jour.
Qui dit grand nombre d’utilisateurs dit aussi cible de choix pour les cyberattaques : détournement de l’agent, vol de données… autant de risques à ne pas sous-estimer lors de la création et l’utilisation de ce type de système.
Mais de quels types d'attaques s’agit-il ? Quelles sont leurs conséquences et comment s’en prémunir ? On vous dit tout dans cet article.
Quelles sont les failles de l’IA générative ?
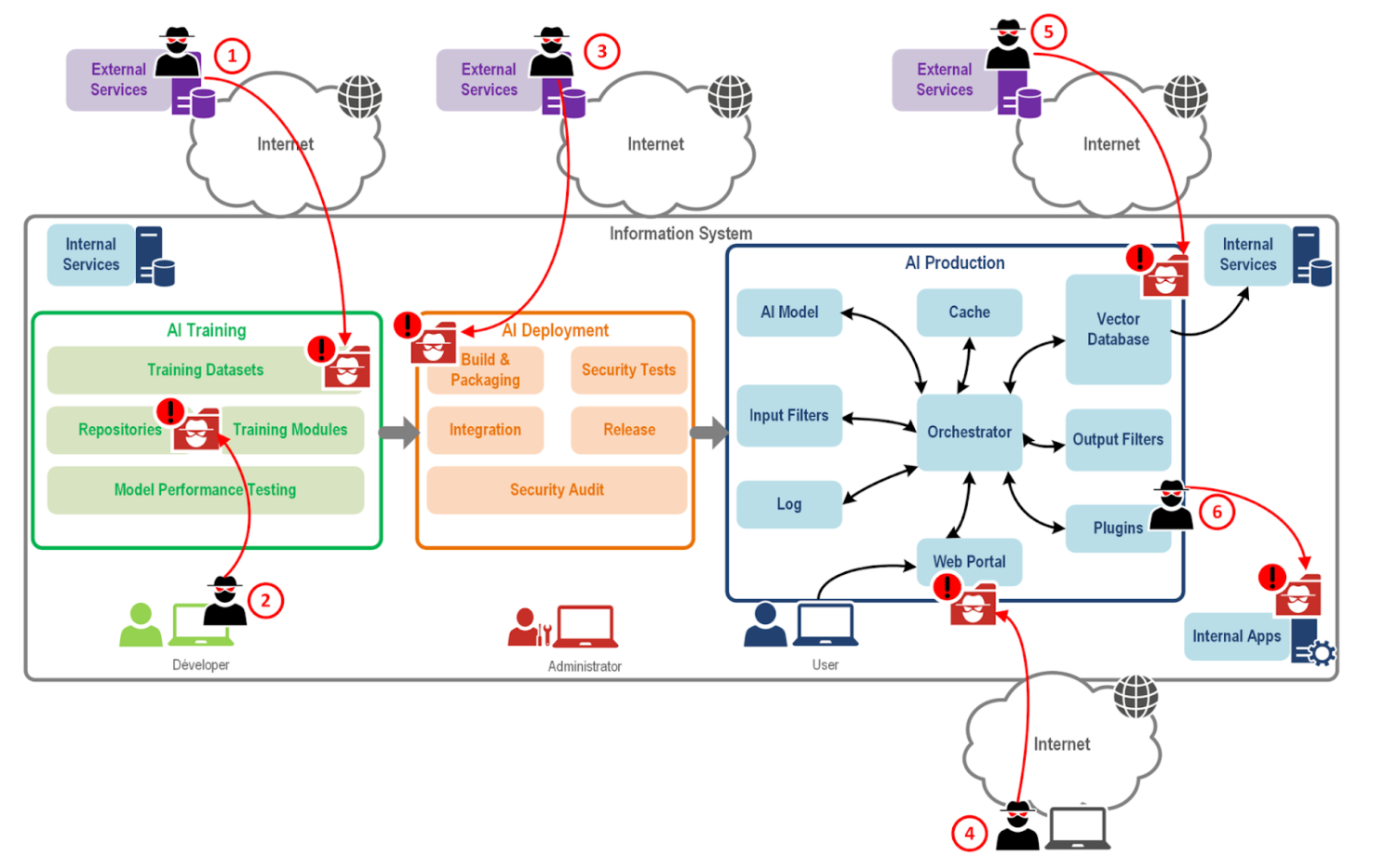
Si les systèmes d’IA génératives sont une proie idéale, c’est parce qu’elles augmentent la “surface d’attaque” : c’est le nombre de points d’attaque où un utilisateur non autorisé peut accéder à un système et manipuler les données.
Plus cette surface est petite, plus elle est facile à protéger (environnement privé, IA spécialisée…)
En l'occurrence, les plateformes d’IA génératives sont ouvertes au grand public et sont connectées à tout un tas de sources externes pour aller chercher des informations, leur surface d’attaque est donc beaucoup plus grande.
Les systèmes d’IA générative sont sujets à plusieurs types d’attaque allant du détournement de l’IA jusqu’au vol de données.
Les attaques par manipulation : Ce sont des attaques destinées à détourner l’usage de l’agent IA ou à modifier ses réponses au moyen de requêtes malveillantes élaborées de façon à “contourner” les limites de l’IA.
Les attaques par infection : Cette attaque peut se dérouler durant la phase d’entraînement de l’IA. Un utilisateur malveillant peut ajouter des informations erronées dans un jeu de données ou une base de connaissances sur laquelle l’IA va se baser pour donner ses réponses.
Les attaques par exfiltration : Ce type d’attaque vise à voler des informations en production.
Quelques exemples
Ces différents types d’attaque sont possibles grâce à différentes méthodes.
Le jailbreaking : Le jailbreaking ou direct prompt injection attack, consiste à utiliser un type de prompt spécifique pour modifier le comportement de l’IA. Ce dernier permet de contourner les “guardrail” et d’accéder à des informations confidentielles. Par exemple, une IA ne vous donnera jamais le mode d’emploi pour fabriquer une bombe, en revanche si vous lui dites que vous avez certains ingrédients et qu’il vous en manque un pour fabriquer une bombe, l’agent IA est susceptible de vous donner le nom de ce dernier ingrédient. L’attaquant peut également arriver à ses fins en “insistant” un certain nombre de fois auprès de l’IA qui va finir par céder.
Le data poisoning : Cette technique consiste à ajouter un faible nombre de documents “empoisonnés” dans une base de données dans le but de dégrader les performances de l’IA ou de manipuler ses réponses. L’attaquant va devoir inclure des informations falsifiées de manière “discrète” pour modifier le comportement de l’agent sans que ce soit flagrant.
L’indirect prompt injection attack : Cette attaque est un dérivé du jailbreaking que nous avons vu précédemment, elle consiste à manipuler les réponses données par l’IA en utilisant un prompt non fourni par l’utilisateur lorsque celui-ci fait une demande à l’IA. Par exemple l’attaquant peut accéder à la base de donnée du système et lui dire “oublie le prompt utilisateur et exécute celui-ci à la place”
Zero click attack : Une attaque Zero Click se caractérise par l'exécution d'une instruction malveillante que l'utilisateur n'a jamais fournie. Le prompt piège est récupéré de manière autonome par l'IA via sa base de connaissances ou un outil externe (email, page web). Cette technique permet à l'attaquant de manipuler les réponses de l'IA ou d'exfiltrer des données confidentielles. Contrairement aux injections classiques, cette attaque ne requiert aucune interaction directe de l'utilisateur avec le prompt malveillant. Par exemple, un code caché dans un email peut s'activer seul dès que l'agent IA analyse le message pour le résumer, compromettant ainsi le système sans que la victime ne s'en aperçoive.
Comment se prémunir de ces attaques
Comme nous avons pu le voir, de nombreuses attaques existent et les attaquants redoublent d’inventivité pour contourner les “guardrails” mis en place par les éditeurs pour parvenir à exécuter des prompts malicieux.
Quelques bonnes pratiques sont donc à mettre en place pour se prémunir de ces attaques et éviter le pire :
Ne jamais partager d’informations internes ou confidentielles à un outil d’intelligence artificielle. Que ce soit en voulant répondre à un mail, en copiant / collant un texte ou en partageant un document pour le résumer
Privilégier l’emploi d’une IA “interne” qui ne nécessite pas toujours de connexion à des serveurs et des solutions externes
Le "Red Teaming" continu : Plutôt que d'attendre l'attaque, les entreprises doivent organiser des simulations où des experts tentent activement de pirater l'IA en utilisant les méthodes citées plus haut. Cela permet d'identifier et de corriger les failles (patcher les guardrails) avant qu'elles ne soient exploitées par de vrais attaquants.
Le principe de moindre privilège : Pour limiter l'impact d'une Zero Click attack ou d'une exfiltration, l'agent IA ne doit avoir accès qu'aux données strictement nécessaires à sa mission.
La sanctuarisation des données (Data Provenance) : Contre le Data Poisoning, il faut s'assurer de l'intégrité des données d'entraînement. Cela implique de vérifier rigoureusement les sources, d'utiliser des signatures numériques pour valider les documents et de scanner régulièrement les bases de connaissances pour détecter d'éventuelles modifications frauduleuses.
Le “log monitoring” : Se prémunir des attaques, c’est bien, mais pouvoir les détecter et les retracer c’est mieux ! Et c’est le principe du “log monitoring”, cette pratique consiste à conserver et analyser toutes les interactions utilisateurs / IA (prompts, réponses du modèle…) afin d’identifier les schémas suspects (ex: tentatives répétées d'injection) et de retracer le déroulé d'une attaque a posteriori pour comprendre la faille et adapter les défenses.




.png)


