
Trusted AI
·
July 16, 2026
AI act : les clés pour mettre votre entreprise en conformité
l'AI Act entrera dans sa phase d'adoption finale de ce mois d'août, êtes-vous prêts ?
Découvrez ce premier épisode de la mini série de notre glossaire qui décrypte 50 mots derrière l'IA


L’intelligence artificielle (IA) est aujourd’hui au cœur de la transformation numérique. Des assistants vocaux aux recommandations personnalisées, en passant par la génération de texte ou d’images, elle s’impose dans tous les secteurs. Mais comprendre l’IA, c’est avant tout comprendre son vocabulaire !
Ce glossaire de l’intelligence artificielle a été conçu pour aider à décrypter ces notions clés et à mieux saisir comment les machines apprennent, analysent et prennent des décisions.
Avant de plonger dans les technologies avancées, commençons par les fondations de l’IA, les concepts essentiels pour comprendre comment elle fonctionne, comment elle s’entraîne et comment elle transforme notre rapport à la donnée. ⚙️
Les fondations de l’intelligence artificielle : ce qu’il faut saisir avant de plonger dans les modèles et les algorithmes.
Champ scientifique qui cherche à reproduire ou à simuler certains comportements humains tels que comprendre, apprendre, raisonner ou créer, l’intelligence artificielle combine mathématiques, informatique et données pour accomplir des tâches complexes. Son objectif est de concevoir des systèmes capables de s’adapter à leur environnement, d’améliorer leurs performances de manière autonome et, à terme, d’assister l’humain dans la prise de décision ou la résolution de problèmes.
Suite d’instructions logiques et ordonnées permettant à une machine d’exécuter une tâche précise. C'est la base de tout programme informatique : chaque algorithme transforme une entrée en une sortie via un raisonnement défini. En IA, il sert à traiter les données, entraîner les modèles et guider leurs décisions.
Branche de l’IA où les modèles apprennent à partir des données sans être explicitement programmés. Le système identifie des motifs, améliore ses performances et ajuste ses prédictions au fil de l’expérience. C'est le moteur derrière la plupart des applications modernes d’IA.
Méthode d’entraînement dans laquelle un modèle apprend à partir de données déjà étiquetées, chaque exemple lui indiquant la bonne réponse. En observant ces correspondances, il apprend à reconnaître des schémas et à généraliser ses connaissances. Cette approche est largement utilisée pour des tâches comme la classification, la prédiction ou la reconnaissance d’images.
Contrairement au précédent, ici les données ne comportent pas de labels : le modèle explore seul et cherche des structures cachées, comme des regroupements, des corrélations ou des tendances, une approche clé pour la segmentation ou la détection d’anomalies.
Inspiré du comportement humain, il repose sur le principe de récompense et de punition : un agent apprend par essais et erreurs, ajustant ses actions pour maximiser un score de performance, une approche utilisée dans la robotique, les jeux ou l’optimisation de systèmes complexes.
Système organisé permettant de stocker, structurer et interroger efficacement les informations, elles constituent le socle de tout projet d’IA en garantissant la disponibilité et la qualité des données, une bonne base de données assurant la fiabilité des modèles entraînés dessus.
Tâche consistant à attribuer une catégorie à une donnée selon ses caractéristiques. La classification permet par exemple de déterminer si un e-mail est un “spam” ou “non-spam”. Elle repose sur des modèles capables d’apprendre à partir d’exemples étiquetés afin de reconnaître des schémas et de généraliser ces apprentissages à de nouvelles données.
Lien statistique entre deux variables, la corrélation décrit la tendance de l’une à varier lorsque l’autre change. Toutefois, corrélation ne signifie pas causalité : deux phénomènes peuvent sembler liés sans qu’il existe de relation directe entre eux. Comprendre cette distinction est essentiel pour interpréter correctement les données et éviter de tirer de fausses conclusions dans les modèles d’IA.
Informations parasites ou non pertinentes présentes dans un jeu de données. Le bruit peut provenir d’erreurs de mesure, de saisie ou de phénomènes aléatoires qui n’ont pas de valeur explicative. Trop de bruit peut perturber l’apprentissage d’un modèle et fausser ses prédictions. Réduire le bruit, c’est améliorer la clarté du signal utile et renforcer la fiabilité des analyses.
Matière première de toute intelligence artificielle, les données nourrissent les modèles, influencent leurs résultats et déterminent leur fiabilité. Plus elles sont riches, variées et bien structurées, plus l’IA gagne en performance, en précision et en pertinence dans ses prédictions comme dans ses décisions.
Phénomène au cours duquel un modèle apprend trop fidèlement les données d’entraînement, jusqu’à en mémoriser les moindres particularités. Le surapprentissage réduit sa capacité à s’adapter à de nouvelles situations. Le modèle devient alors très performant sur son jeu d’apprentissage, mais peu efficace face à des données inédites. Éviter ce phénomène est essentiel pour garantir la capacité du modèle à généraliser et à produire des résultats fiables dans des contextes réels.
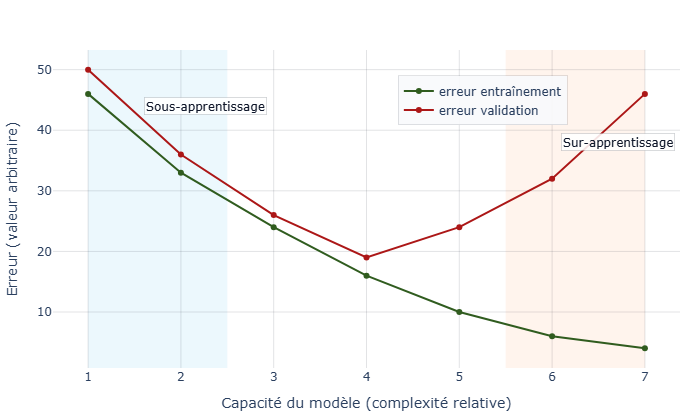
Phase durant laquelle un modèle apprend à reconnaître des motifs ou à effectuer des prédictions. L'entraînement consiste à ajuster progressivement ses paramètres afin de réduire les erreurs entre ses résultats et les valeurs attendues. Étape cruciale du développement d’un système d’IA, elle demande souvent des ressources importantes en temps et en puissance de calcul, mais conditionne directement la performance et la fiabilité du modèle final.
Élément mesurable ou propriété utilisée par un modèle d’IA pour apprendre à partir des données. Par exemple, la couleur ou la taille d’un objet peuvent être des features dans un modèle de vision. La qualité et la pertinence des caractéristiques influencent directement la précision et la performance du modèle.
Représentation mathématique d’un phénomène, le modèle d’IA est entraîné à partir de données afin d’en capturer les régularités et les schémas. Il apprend à prédire, à classer ou à générer de nouvelles informations selon les exemples qu’il a reçus. Sa performance dépend étroitement de la qualité, de la diversité et de la pertinence des données utilisées, ainsi que du soin apporté à son entraînement.
Ensemble de pratiques qui unissent le machine learning, le développement logiciel et les opérations IT afin d’industrialiser les projets d’intelligence artificielle. Le MLOps vise à automatiser tout le cycle de vie d’un modèle, de son entraînement à son déploiement en production, tout en assurant une surveillance continue. Il facilite la collaboration entre data scientists et ingénieurs et garantit la fiabilité, la traçabilité et la performance des modèles utilisés à grande échelle.
En maîtrisant ces concepts, on pose les fondations nécessaires pour saisir comment l’IA apprend, s’adapte et prend des décisions.
Mais connaître les principes ne suffit pas : il faut aussi comprendre les technologies qui propulsent l’IA, celles qui permettent la reconnaissance d’images, le traitement du langage naturel ou encore la génération de contenu.
Poursuivez votre exploration dans la deuxième partie : Les technologies qui propulsent l’IA et téléchargez notre glossaire : "Les 50 mots derrière l'IA".
Prêt à voir ce que vos données ont vraiment à dire ? Laissez-les parler avec nos experts. Contactez-nous dès maintenant.




