
IA de confiance
·
July 16, 2026
AI act : les clés pour mettre votre entreprise en conformité
l'AI Act entrera dans sa phase d'adoption finale de ce mois d'août, êtes-vous prêts ?
We will try to provide some answers to this questions in two parts. This first article focuses on conception, data collection, exploration and application prototyping while the second one focuses on the first deployment of the solution and iterations to quickly improve it.


.png)
At a time when the world is exalting itself in front of the power of generative AI thanks to models accessible from any web browser such as GPT-4 (OpenAI), Bard (Google) or LLaMA (Meta), one could think that "the implementation of an AI is child's play". This is not the case in companies, where 80% of projects still struggle (and fail) to be used in real conditions by end users (source: Gartner). As we have previously presented, MLOps increases the chances of success by providing a new project framework and methodology that are much more iterative and virtuous, not only for production.
For Data Scientists, key players in the AI applications development, it is the best and the fastest way to get closer to end users, to shed light on the value of their work and to reduce friction at all stages. From the first brainstorm at the coffee machine to the on-site training of users, MLOps will ease the project and the team interactions. To better understand this, let's put ourselves in the shoes of a data scientist. At 10am, after your daily meeting, your favorite Product Owner comes to see you to ask you to develop a new use case : “we need it in 2-3 weeks and we need it to be sharp” are your only instructions… No time to loose, let's get started!

After having framed the use case objectives with the business team representatives, you’re ready to gather some data. Data are indeed the starting point of every Machine Learning project and it remains the cornerstone of any AI application throughout its lifecycle. Gathering data, exploring it and assessing its quality is a crucial but often tedious task for every data scientist.
First, data need to be accessed and stored somewhere. For that you will need an access to a database whether it is relational like Postgres, or NoSQL like a MongoDB or key/value like a S3 Amazon Cloud storage. This database should be secured with access rights so that the data are safe and it won’t be accidentally altered, deleted or leaked. It must also be reliable so that data are accessible efficiently any time both for experimentation and in production. This requires a lot of infra and Ops knowledge which are not always available or cheap. It can take days or weeks to setup a decent data infrastructure depending on the requirements of the application.
Having fast, robust, secure and monitored data storage is so crucial in any AI application that a data scientist should be able to create one as easily as he creates a ML model. MLOps provides you with tools to setup the desired type of database easily, almost instantly and ready for production from the get go. All you have to do is choose the database type that best suits your data and you are done, your data will be reliably accessible at any time.
Having production grade data storage from the start will not only save you a lot of time in experimentation due to faster and more reliable data access, but it will also allow you to work on real world production data as soon at it is available, removing the often painful transition from initial static data sources to the live data your model was really meant to work on. This also significantly mitigate the risk to see your model that works great on experiment data, fail on real world data that often have a different distribution.
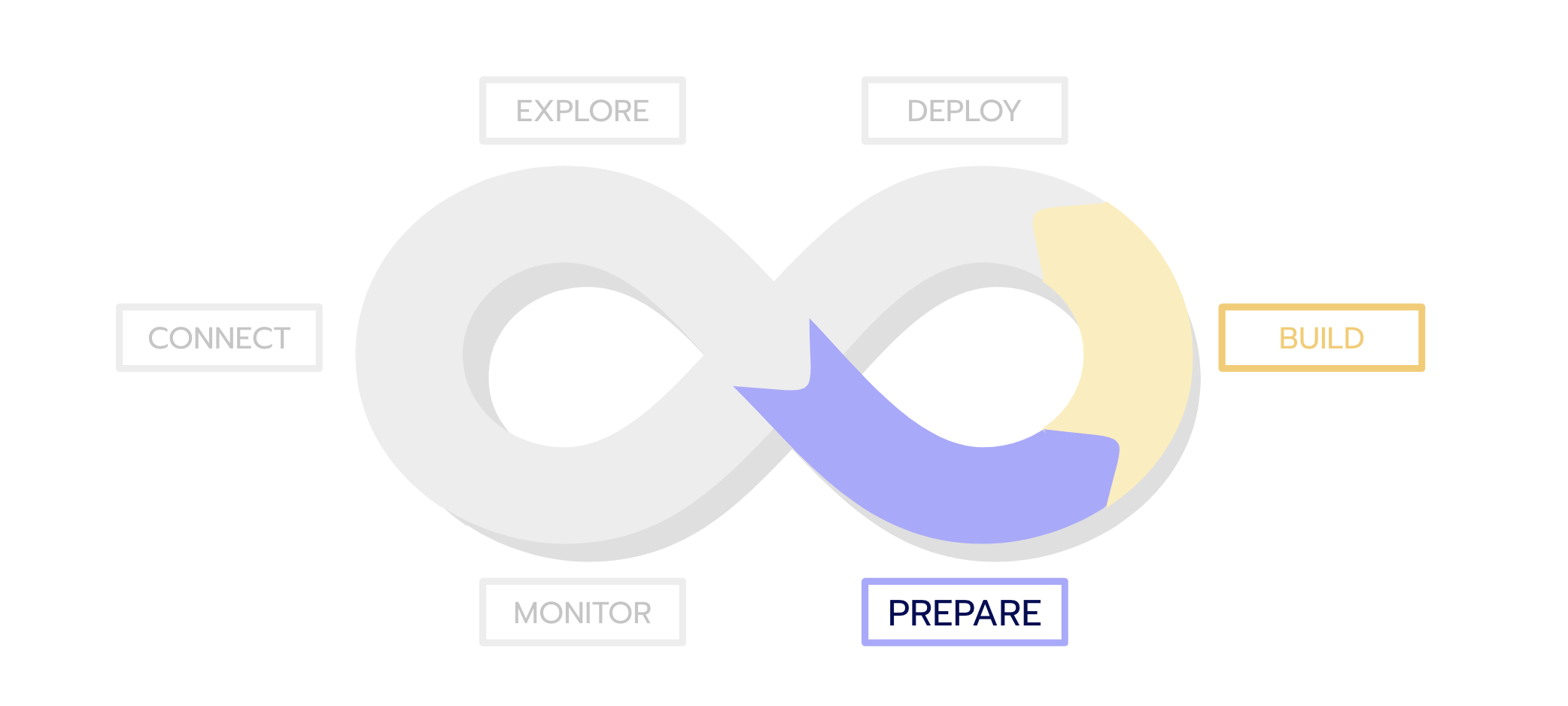
With a solid data infrastructure at your disposal, you can now start building your model. It usually involves a lot of experimentation, trial and errors to test various approaches, different models, choose the appropriate features, explore new data sources, work on pre and post processing … It has become so easy to build models and features that you often end up with tens if not hundreds of experiments before releasing your first model into production.
You want to evaluate and compare all those experiments regarding a set of relevant indicators for your application, for instance ML metrics like RMSE or confusion matrix, analyze some prediction samples to understand how your model behaves … The huge number of experiment combined with the diversity of indicators used for evaluation usually makes it really difficult to properly compare and select the appropriate model for production which lets you stuck in the experimentation phase for a very long time.
The solution that MLOps brings to this problem is two fold.
First in the MLOps framework putting a model into production is made so easy that you should put your first model in production as soon as it is reasonably performant (this criteria depends on the use case of course) and to improve it iteratively putting a new model in production as soon as you have an acceptable improvement. Stop experimenting for ages, waiting to have the perfect model but rather improve your production model gradually. This way, at each iteration you only have to compare a handful of experiments that were designed to improve a specific part of the model, which is much easier but also more efficient. This also allows you to focus on improving real world meaningful metrics such as user adoption indicators. Structuring your models in pipelines can help a lot in that regard since it will greatly improve the modularity of your application so you can focus on one step at each iteration.
.png)
Secondly, more and more experiment tracking tools are integrated to the MLOps ecosystem. These tools helps you centralize all the useful information related to an experiment such as the model and the code that has been used, the hyper parameters, the version of dataset, and all the related metrics and visualizations. Wherever all those elements are stored, you can still analyze and compare all your experiments in one graphical interface.
As we saw, MLOps is a project management methodology that enables Data Scientists to develop user-centric AI applications with better communication between stakeholders and fast iteration. This approach facilitates data infrastructure set-up, model creation and improvement, deployment and monitoring, as well as feedback collection for continuous improvement. Data Scientists can thus focus on end-user satisfaction and reduce frictions at every stage of the AI application lifecycle. In a second part, we will focus on deployment and interaction with users.
Le cas particulier des GPAI (Modèles d'IA à usage général) : Les grands modèles de langage (LLM) comme Mistral AI, OpenAI ou Claude entrent dans un régime propre. Soumis à une application progressive, ils nécessitent des analyses d'impact approfondies pour évaluer les risques selon s’ils sont utilisés bruts, fine-tunés ou intégrés via API.
Développée par Xavier Trigano, la méthode RADAR permet à toute organisation de piloter sa mise en conformité de manière itérative :
Focus "AI by Design" - L'exemple du tri automatique de CV : Un outil RH qui exclut ou accepte des candidats de manière 100 % autonome est classé "Haut Risque", avec un coût de conformité très lourd. La méthode RADAR recommande plutôt une approche by design : modifier les fonctionnalités de l'outil pour en faire un simple système d'aide à la décision (qui extrait les compétences clés du CV mais laisse la validation finale à un recruteur humain). L'outil apporte la même valeur métier, mais bascule en risque limité, allégeant drastiquement les contraintes légales.
Comment lutter contre le Shadow AI en entreprise ?
L'interdiction pure et simple ne fonctionne pas. Pour maîtriser l'usage des LLM par les collaborateurs, la réponse doit être transverse :
L'usage des LLM (ChatGPT, Claude...) viole-t-il le RGPD ?
Ce n'est pas l'outil qui caractérise la violation, mais la finalité de l'usage. Reformuler une campagne marketing sur Claude ne présente aucun risque RGPD. En revanche, y injecter l'intégralité du fichier RH de la pyramide des âges de l'entreprise sans précaution constitue un manquement grave.
Des alternatives souveraines (hébergées on-premise ou sur des clouds français/européens) permettent de pallier les risques liés au Cloud Act américain tout en garantissant une efficacité équivalente.
Comment encadrer mes équipes dans leur utilisation de l’IA ?
L'IA Act impose une obligation de formation pour tous les utilisateurs au sein de l'organisation. L'IA pouvant se tromper ou halluciner, seul l'esprit critique de l'humain formé permet de couvrir ce risque résiduel et d'assurer un contrôle qualité efficace.
L'IA Act ne doit pas être perçu comme un frein à l’innovation, mais comme un cadre de confiance.
En intégrant la conformité dès la conception des projets, l'IA devient un levier pérenne de performance économique, d'acceptabilité sociale et de souveraineté.
Envie de développer votre agent IA sur-mesure conforme à la réglementation AI Act ? Contactez nos équipes.
Et accédez au replay de ce webinaire dès maintenant !



.png)