
IA de confiance
·
July 16, 2026
AI act : les clés pour mettre votre entreprise en conformité
l'AI Act entrera dans sa phase d'adoption finale de ce mois d'août, êtes-vous prêts ?
This article is an introduction to the paper written by Hugo Koubbi, Matthieu Boussard and Louis Hernandez, from Craft AI R&D Team.


The LoRA algorithm seems to be the most widespread fine-tuning method for LLMs. LoRA reduces parameter count by employing low-rank matrix factorization on attention mechanisms. In “The Impact of LoRA on the Emergence of Clusters in Transformers” with Matthieu Boussard and Louis Hernandez, we study the impact of LoRA on tokens.
Based on the framework proposed by Sander et al. we have adopted a simplified Transformers architecture. In line with the concept of neural ODEs, we view the layers as time, and the tokens as an interacting particle system.
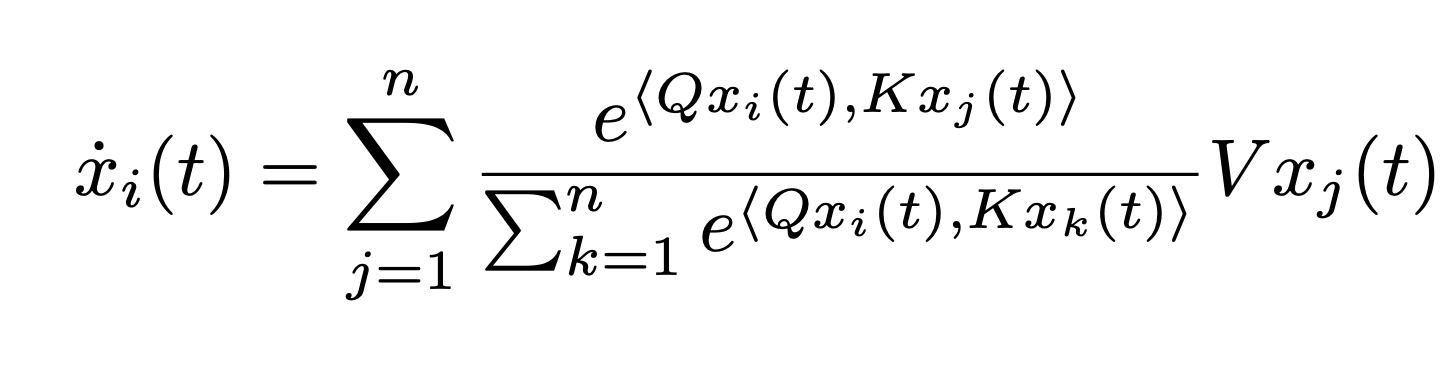
In “The emergence of clusters in self-attention dynamics” and “A mathematical perspective on Transformers” Geskovski et al. demonstrated that the dynamic asymptotically leads to the formation of token clusters. In this study, we investigate the impact of LoRA fine-tuning on cluster formation in Transformers.
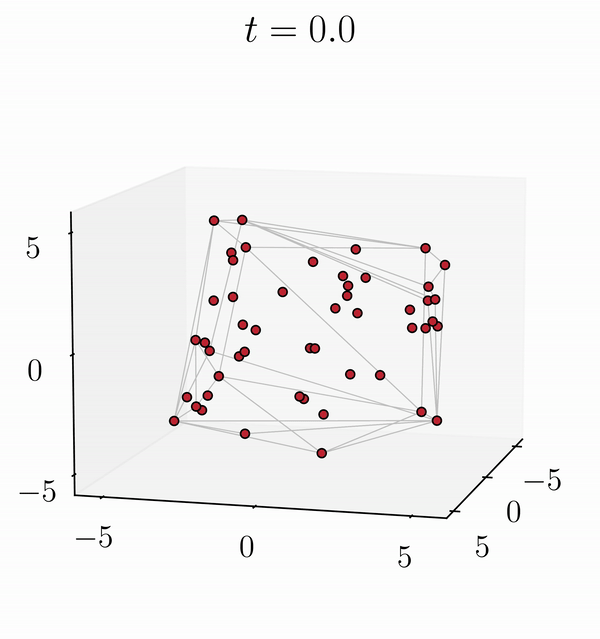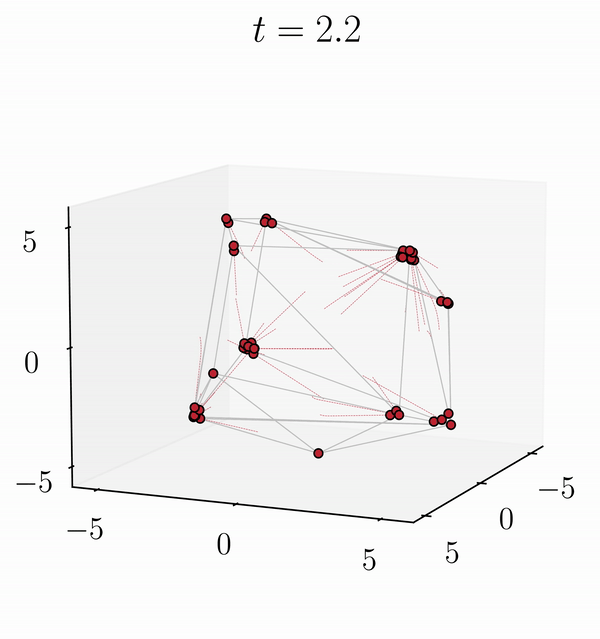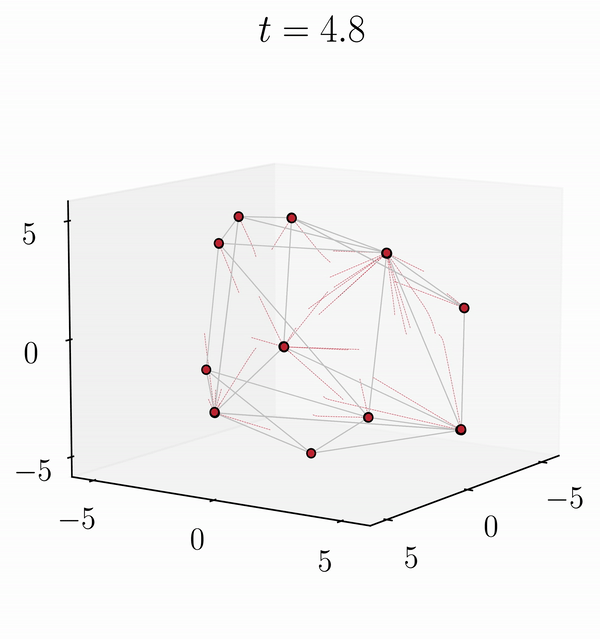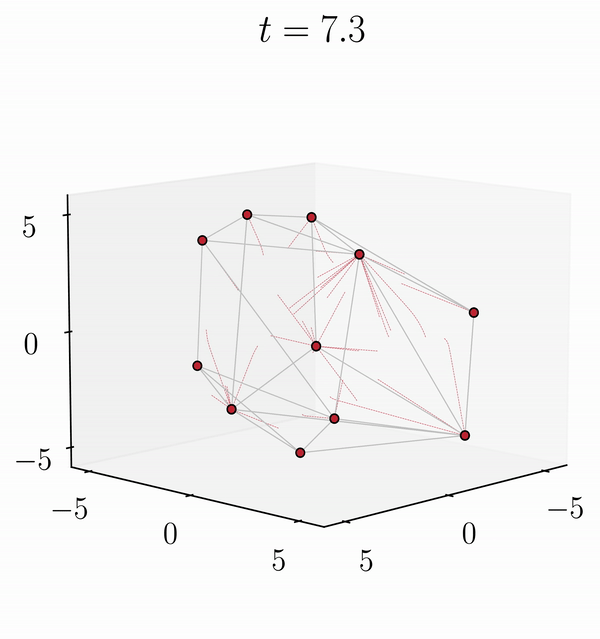
We establish short-term stability results for attention matrix parameters. Our findings reveal that even if long-term dynamics of tokens with the same initial conditions diverge, on a short-term scale, the two trajectories are close.
If only the attention matrix V is changed, the tokens of the modified trajectory initially follow a similar pattern to the original dynamics before diverging towards a new clustering (Original dynamic on the left and LoRA dynamic on the right).
.gif)
We also establish a theoretical upper bound on the time of formation of the second cluster. Additionally, we numerically investigate this bound for optimality.

Motivated by empirical and theoretical results on the bias of $ QK^{T} $ attention matrices towards low-rank matrices, we studied clustering structures in this case. We have highlighted new clustering structures.
We have also shown in a simplified framework how LoRA can be used to create new clustering structures (LoRA dynamic on the left and the original on the right).

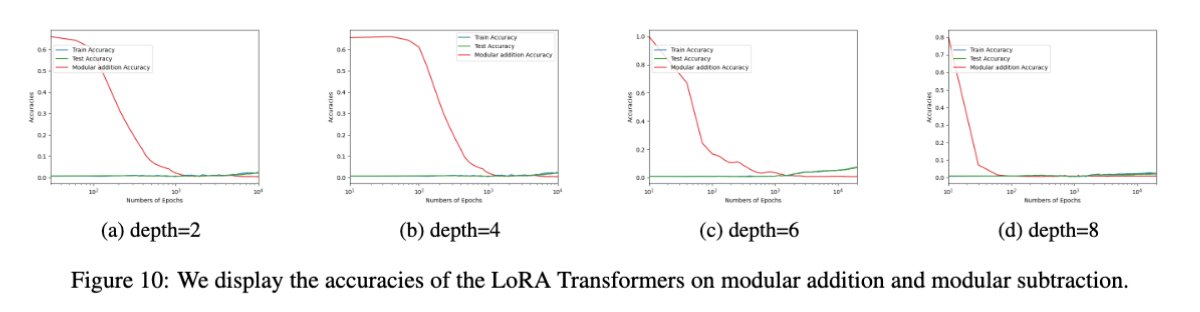
We also trained the architecture considered in the article on modular addition, and then fine-tuned it for modular subtraction. As an illustration of our results, the deeper the model, the faster the accuracy decreases during fine-tuning.
Even if our hypotheses are rather simplistic, it seems that the clustering phenomenon also appears in LLMs such as Llama2 7B.

Le cas particulier des GPAI (Modèles d'IA à usage général) : Les grands modèles de langage (LLM) comme Mistral AI, OpenAI ou Claude entrent dans un régime propre. Soumis à une application progressive, ils nécessitent des analyses d'impact approfondies pour évaluer les risques selon s’ils sont utilisés bruts, fine-tunés ou intégrés via API.
Développée par Xavier Trigano, la méthode RADAR permet à toute organisation de piloter sa mise en conformité de manière itérative :
Focus "AI by Design" - L'exemple du tri automatique de CV : Un outil RH qui exclut ou accepte des candidats de manière 100 % autonome est classé "Haut Risque", avec un coût de conformité très lourd. La méthode RADAR recommande plutôt une approche by design : modifier les fonctionnalités de l'outil pour en faire un simple système d'aide à la décision (qui extrait les compétences clés du CV mais laisse la validation finale à un recruteur humain). L'outil apporte la même valeur métier, mais bascule en risque limité, allégeant drastiquement les contraintes légales.
Comment lutter contre le Shadow AI en entreprise ?
L'interdiction pure et simple ne fonctionne pas. Pour maîtriser l'usage des LLM par les collaborateurs, la réponse doit être transverse :
L'usage des LLM (ChatGPT, Claude...) viole-t-il le RGPD ?
Ce n'est pas l'outil qui caractérise la violation, mais la finalité de l'usage. Reformuler une campagne marketing sur Claude ne présente aucun risque RGPD. En revanche, y injecter l'intégralité du fichier RH de la pyramide des âges de l'entreprise sans précaution constitue un manquement grave.
Des alternatives souveraines (hébergées on-premise ou sur des clouds français/européens) permettent de pallier les risques liés au Cloud Act américain tout en garantissant une efficacité équivalente.
Comment encadrer mes équipes dans leur utilisation de l’IA ?
L'IA Act impose une obligation de formation pour tous les utilisateurs au sein de l'organisation. L'IA pouvant se tromper ou halluciner, seul l'esprit critique de l'humain formé permet de couvrir ce risque résiduel et d'assurer un contrôle qualité efficace.
L'IA Act ne doit pas être perçu comme un frein à l’innovation, mais comme un cadre de confiance.
En intégrant la conformité dès la conception des projets, l'IA devient un levier pérenne de performance économique, d'acceptabilité sociale et de souveraineté.
Envie de développer votre agent IA sur-mesure conforme à la réglementation AI Act ? Contactez nos équipes.
Et accédez au replay de ce webinaire dès maintenant !



.png)