
IA de confiance
·
July 22, 2026
La gouvernance des données au cœur du déploiement de l’IA
Découvrez dans ce livre blanc comment structurer vos données et lancer des projets d'IA maîtrisés et durables.
MLOps, short for Operational Machine Learning, is a practice that combines DevOps principles with the development and deployment of Machine Learning models. By automating and streamlining the entire lifecycle, from data preparation to model scaling, MLOps enables organizations to effectively leverage data for real-time, large-scale ML applications. In this context, Python libraries like Pandas and Polars play a crucial role, offering powerful data processing capabilities. Comparing these libraries helps optimize MLOps workflows, ensuring efficient and successful ML deployments.


Polars emerge as a compelling alternative to Pandas, with this article you will be convinced of the following benefits.
Pandas and Polars are two Python data processing libraries that offer similar functionalities but with different approaches. Pandas is the de facto data processing library in Python, allowing manipulation of data arrays, known as DataFrames, with a simple and expressive syntax. It is highly popular among data scientists and developers due to its feature-richness and flexibility.
On the other hand, Polars is a newer data processing library that focuses on performance and extensibility. Written in rust, it efficiently handles data arrays, even for large volumes of data, and is designed to work in parallel, leveraging the computational capabilities of modern processors to provide high-performance data processing. Polars is built on Arrow, inherently different from Pandas which is index-based, that allows constant-time random access, zero-copy access and overall cache-efficient data processing.
Although Pandas is the most widely used data processing library in Python, it may have inadequate performance for processing large quantities of data or complex operations. On the other hand, Polars may have a steeper learning curve due to its different syntax, but it can offer significantly faster performance for intensive data processing operations.
In the following section, we will explore a concrete case of data preparation for a Machine Learning model using Pandas and Polars, to show their differences in syntax and performance.
To illustrate the differences between Pandas and Polars, we will work on a dataset representing information about used cars.The dataset comprises 3 million real-world used car details obtained from a self-made crawler on Cargurus inventory in September 2020, intended for academic, research, and individual experimentation. It serves as an inspiration for building a web application that can estimate the listing price of a vehicle and prompts consideration of the relevant features to construct a price prediction regression model.
For practical matters, we will limit our test to 250 000 rows. Further tests can easily be done leveraging the JUPYTER NOTEBOOK we put at your disposal.
For the sake of an impartial evaluation, we use the following functions to evaluate the time and memory cost of Pandas and Polars functions.
The objective of this exercise is to explore and prepare the data as if we were preparing to train a Machine Learning model that must predict the selling price of a used car according to its characteristics. Let’s now explore several operations in both Pandas and Polars.
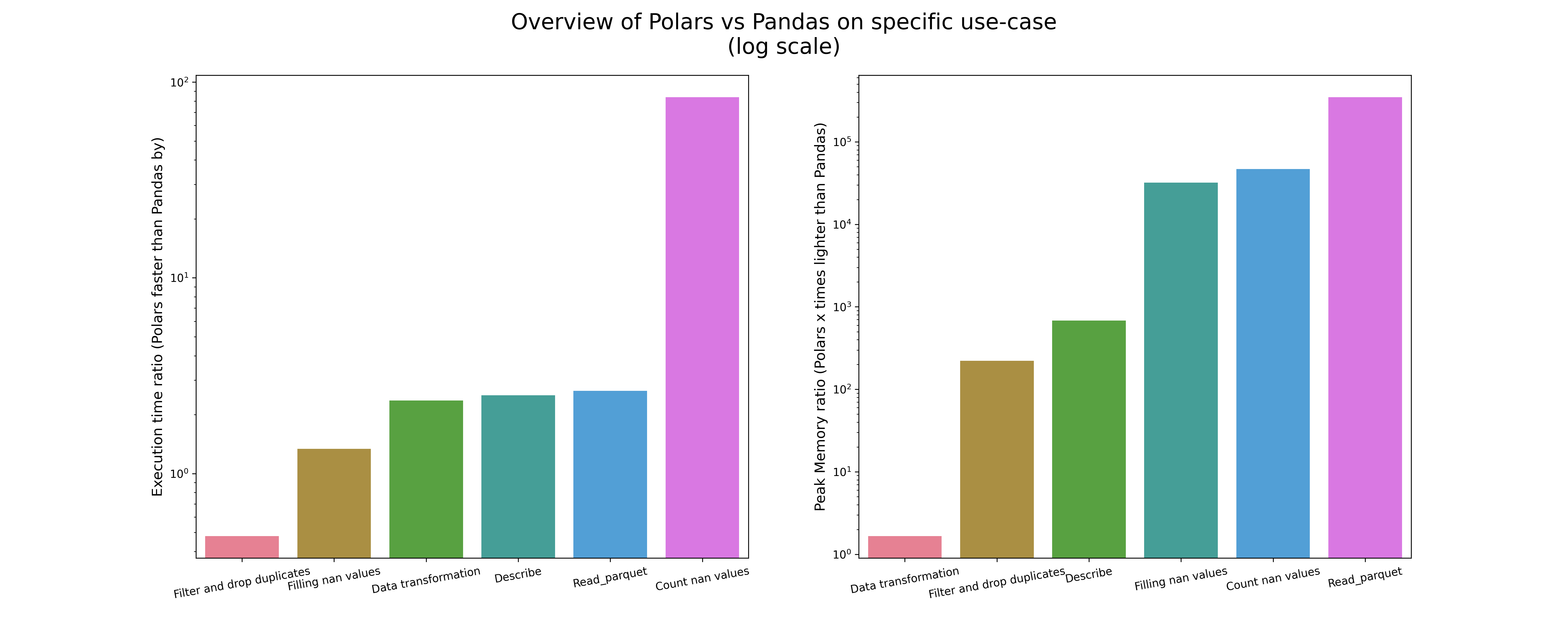
In all but one operation Polars is faster than Pandas; in every Polars is the lightest. While the speedup can be small, it reaches in our use-case up to 50 times faster than the Pandas alternative, which is far from being negligible. From a syntax point of view, it is strikingly easy to shift to Polars with the only exception of shifting to the lazy-API mode.
This set of examples, while being restricted, provides a strong case for the superiority of Polars and the ease of code adaptation.
Polars is designed with a focus on performance and scalability, making it well-suited for handling large datasets efficiently. It leverages modern parallel computing techniques and takes advantage of the computational capabilities of processors, allowing for faster data processing operations compared to Pandas. This performance boost can be particularly beneficial when dealing with computationally intensive tasks or working with significant volumes of data.
Additionally, Polars provides a more memory-efficient approach to data processing. It utilizes lazy evaluation and optimized memory management strategies, enabling users to work with large datasets that may exceed the available system memory. This can be especially advantageous when dealing with big data scenarios.
As seen throughout this blog Polars offers a similar API to Pandas, making it easy for users familiar with Pandas to transition to Polars seamlessly. This ensures that existing code and workflows can be easily adapted or migrated to Polars, minimizing the learning curve and facilitating a smooth transition. While continuing to manipulate DataFrames in Python and empowering you to create readable and performant code.
The Pandas library can be considered one pillar of the Python data-science ecosystem. It is widely used and benefits from its popularity through a rich ecosystem. Many packages are built on top of pandas for data preparation, analysis and visualization [1]. Polars as a new alternative have no such advantage yet. While not impacting the performance, it has a big importance in the developer's workflow and can justify sticking with Pandas despite the empirical superiority of Polars.
Benefiting from the Arrow columnar format, Polars come with important features such as data adjacency for sequential access, constant-time random access, SIMD and vectorization-friendly as well as true zero-copy access in shared memory.
The Lazy-API is one of the two operational modes of Polars, it only executes the queries once it is ‘needed’. Leveraging this mode can provide a significant performance boost, however, it requires a small learning period as the syntax differs a little from the eager execution mode (closest to Pandas). This mode is particularly suited to execute SQL queries yet Polars is not fully compatible with the SQL language (Pandas is not compatible).
Polars, being a newer library compared to Pandas, has some limitations when compared to its more established counterpart. Firstly, it may have a limited ecosystem integration, lacking the extensive range of third-party extensions and integrations that Pandas offers. Secondly, Polars can present a steeper learning curve due to differences in syntax and functionality, requiring additional time and effort for users already familiar with Pandas. Lastly, Polars may not have the same level of community support and extensive documentation as Pandas, making it potentially more challenging to find specific solutions or troubleshoot complex use cases.
Overall, Polars serves as a compelling alternative to Pandas due to its superior performance, scalability, memory efficiency, and extended functionality. It empowers users to handle larger datasets more efficiently and perform complex data processing operations with ease.
Polars can be seen as a strong contender to Pandas in a similar fashion to how Android is a contender to Apple. Just as Android offers an alternative operating system to Apple's iOS, Polars provides an alternative data processing library to Pandas. Both Android and Polars bring unique features and advantages to the table, fostering competition and choice in their respective domains. While Pandas has been the go-to library for data processing in Python, Polars challenges its dominance by offering superior performance, scalability, and memory efficiency.
Ultimately Polars better suits MLOps, with its focus on performance and scalability, Polars is well-suited for handling large datasets efficiently, which is crucial for MLOps workflows. Its ability to leverage parallel computing techniques and optimize memory management enables faster data processing, facilitating the development and deployment of Machine Learning models at scale. By incorporating Polars into the MLOps pipeline leads to improved efficiency and productivity, and eventually a better industrialisation of machine learning projects.
Pandas documentation:
[1] https://pandas.pydata.org/docs/ecosystem.html
Polars documentation:
https://pola-rs.github.io/polars-book/
Arrow documentation:
https://arrow.apache.org/docs/format/Columnar.html
Dataset:
https://www.kaggle.com/datasets/ananaymital/us-used-cars-dataset
benchmarks:



