
IA de confiance
·
July 22, 2026
La gouvernance des données au cœur du déploiement de l’IA
Découvrez dans ce livre blanc comment structurer vos données et lancer des projets d'IA maîtrisés et durables.
Online retail websites depend on their ability to understand their customer habits and wishes. These websites need to know which type of products interests which visitor and when they should make a suggestion.

%20(1).jpg)
Let’s say you are the proud owner of B2C.com, an online retail website which provides access to a wide variety of products. In order to improve your average revenue per visitor, you want to understand your visitors behavior.
In this article we use an open source dataset to show how customer behavior analysis and machine learning can make a notable impact on every online business revenue.
The data has been collected from a real e-commerce website.The dataset consists of three files : one with all the events (page views), one with products item properties and a file that describes the category tree.
A category of products refers to all the products offering the same general functionality. It is made to organize products and can resemble a tree structure. For example, some common product categories are fashion, food, Decoration, etc. In this data-set, the items are categorized into 360 categories in the first-level. Each of the categories has a higher level category or let say, parent.
There are 25 highest level categories.
From these files we extract the sequence of events with the exact timestamp, the visitor-id and the different category of product the visit was on.
The final file contains more than 2.7 million events of 1 million visitors. More than 400 of the visitors have over 100 event rows. It has three columns: DateTime, visitor id, and category. The DateTime range is between 2015/05 and 2015/09.

Our goal is to predict customers behavior answering two main questions.
If the recent emerging of analytics in mail campaigns showed only one thing, it is that timing matters a lot when it comes to incentives. Answering the first question allows the site owner to send a notification or a mail to their users at the appropriate time. Suggesting the right topic / product at the right moment is a powerful way to increase its daily traffic.
The two questions are rather different. The first one belongs to the one-class classification family, whereas the second is (more classical) multiclass classification. Thereby, different models were used for each problem.
To emit relevant notifications, knowing user habits is a big advantage. Using a model to predict their intent let the website allows the website to take into account every available pieces of information.
We want to find the time boundaries in which the user is more likely to come back to the website.
To be able to detect these boundaries, we need to generate a set of timestamp samples in which the visitor didn't show up. The generation process we use offers two parameters: the mean frequency f and the positive avoidance a. First negative samples are generated according to f. Then they are filtered using a. Negative samples with an actual event closer than the positive avoidance are deleted to reduce fuzziness.
A subset of visitors is chosen to evaluate our different models. Negative samples for the test subset are generated with 20 minutes as the mean frequency and 40 minutes as the positive avoidance. The generation parameters for the training phase were considered as hyperparameters.
To see how well Craft AI performs, we benchmark other popular algorithms:
These algorithms have different parameters that were chosen using cross-validation on the training data set on each visitor.
Craft AI natively handles periodic and time-related features and does not need normalization. This is not the case for the other algorithms. So we applied some transformations on the timestamp. 4 features were generated: month_of_year, day_of_month, day_of_week and hour. Next, we normalized all the columns.
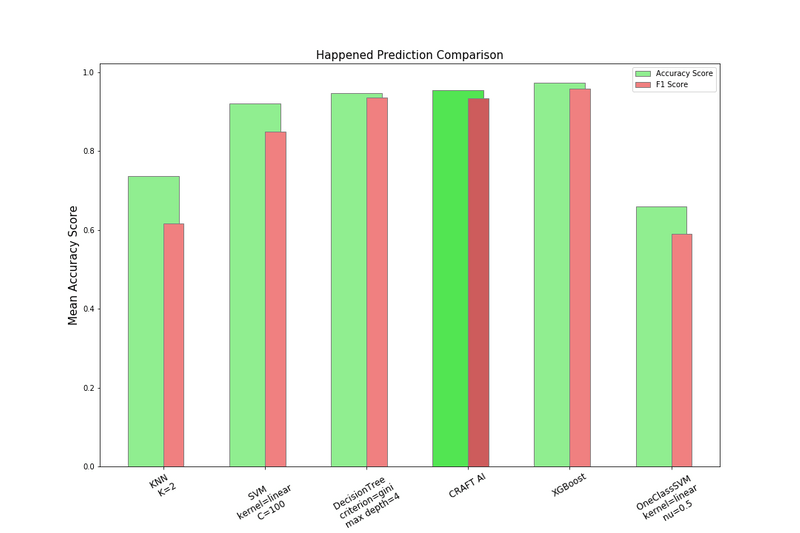
As you can see in this plot, craft ai is the second best model for happened prediction and it has only a bit less accuracy score than a boosting algorithm which is not explicable.
The Craft AI mean accuracy is more than 95%. It means that our model can correctly decide if an event will happen or not in a given time for around 95 percent of the events. The following picture is a sample tree of one of the visitors:
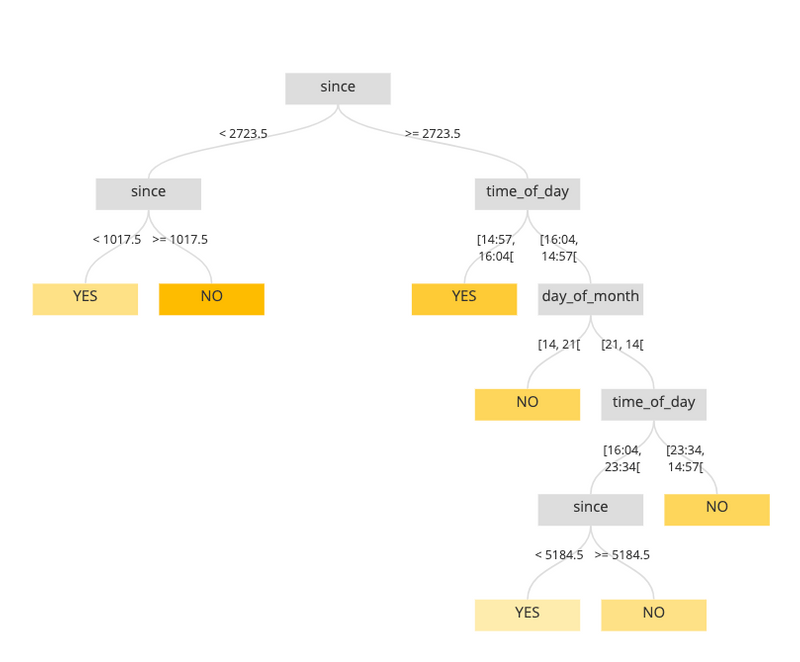
The above decision tree is built based on one of the customer's behavior. Each leaf contains the prediction of an event which can be YES or NO. The path to each leaf shows the sequence of decisions based on time features of the event that leads to the prediction.
For example, we can see in the rightmost leaf that if it’s been more than 2723.5 seconds from the last visit of the visitor if it is between 23:34 and 14:57 and if it is between the 21th of a month and the 14th of the next month, the visitor is not interested currently by the website.
As it was mentioned before, the test set is limited to the actual events that were correctly detected during the Event Prediction Phase by the most accurate algorithm.
On top of the previous preprocessing, another extra feature is added which is the last viewed product category as a new column named ‘last’. This column was transformed to 25 new binary dummies using one-hot encoding.
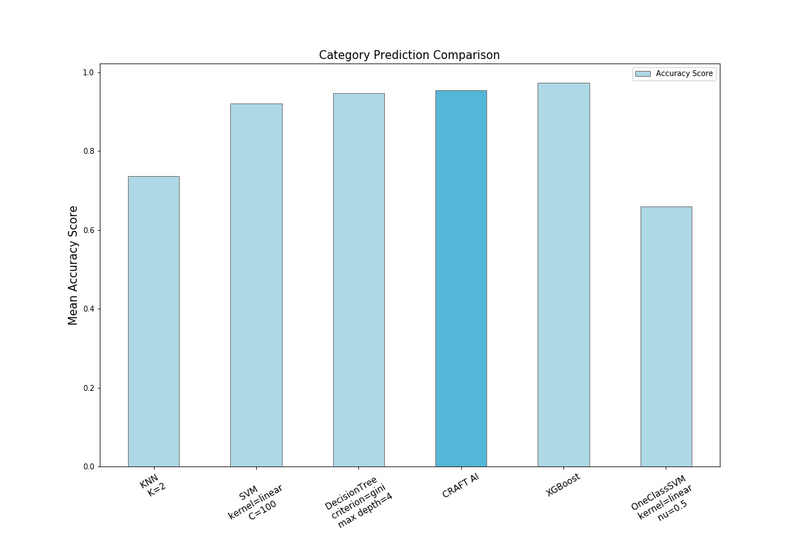
Again, Craft AI is among the very best algorithm. Its very high accuracy (> 90%) shows we can predict which product interests which visitor.
As you've seen in this article, Craft AI can predict the actions of the customers on websites like B2C.com. It also performs as good as other well-known algorithms but with the benefit of explainability.
With the use of these results and knowing more about the visitor's behavior, a website like B2C.com can achieve a lot. Here are two sample use cases:



