This paper presents some of the foundations of Craft AI and especially how we introduced Machine Learning of user habits in an explainable context. It also introduces the initial version of our forgetting method that is able to unlearn lost habits.
·
Jun 7, 2016
This work was presented at PAAMS 2016 in Sevilla (Spain) and published in its proceedings. It was later presented at RFIA 2016 at Clermont Ferrand (France).
Abstract
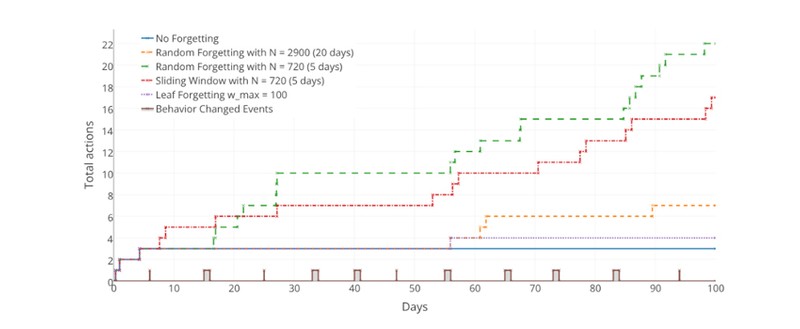
In the Internet of Things (IoT) domain, being able to propose a contextualized and personalized user experience is a major issue. The explosion of connected objects makes it possible to gather more and more information about users and therefore create new, more innovative services that are truly adapted to users. To attain these goals, and meet the user expectations, applications must learn from user behavior and continuously adapt this learning accordingly. To achieve this, we propose a solution that provides a simple way to inject this kind of behavior into IoT applications by pairing a learning algorithm (C4.5) with Behavior Trees. In this context, this paper presents new forgetting methods for the C4.5 algorithm in order to continuously adapt the learning.

.jpg)


.png)


